The worst thing about finding a new apartment is the anticipation that happens during the long periods of inevitable waiting. I got pretty anxious, and decided to try to automate my stress out the window!
I'm looking for apartments on Craigslist, to both save money and hopefully meet people that won't cut me up and put me in little buckets. I decided I'd write a Craigslist scraper in python using the wonderful beautifulsoup HTML parsing library.
This is essentially a data munging exercise. All the data I want (prices, location, washer and dryer combinations) are inside of this website, and whatever I write should just grab it in an organized fashion and put it into something usable. I decided that my output format would be JSON so I can query the information in a more structured way than a CSV. (Plus, a lot of the post titles contained commas, and I'm lazy!)
The Data
The starting point for our data is an index page. It looks something like this:
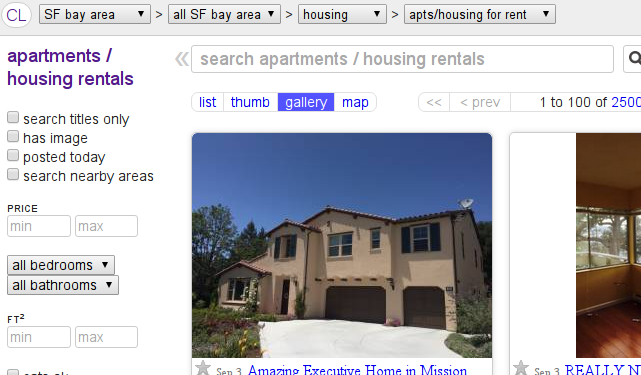
Under the hood, Craigslist will probably output all of their posting data in some kind of a loop, so the source should be pretty predictable:

Bingo! Look at all those <p class="row">! Thankfully, with beautifulsoup, these are really easy to isolate out. I'm going to pretend for the next code block that we have some magical function called get_craigslist_html() that pulls down the whole HTML for that page. We'll fill in the bones on this later.
With beautifulsoup, you can navigate the page's source like a tree. You can use methods like find_all() to pick out individual subtrees of that, which instead of being rooted at <html> are rooted at some arbitrary tag (like <p class="row">!)
source = get_craigslist_html()
rootsoup = BeautifulSoup(source)
for post in rootsoup.find_all('p', 'row'):
# do the stuff
Great, now we can operate on our posts! What's inside of each of those big <p> tags?
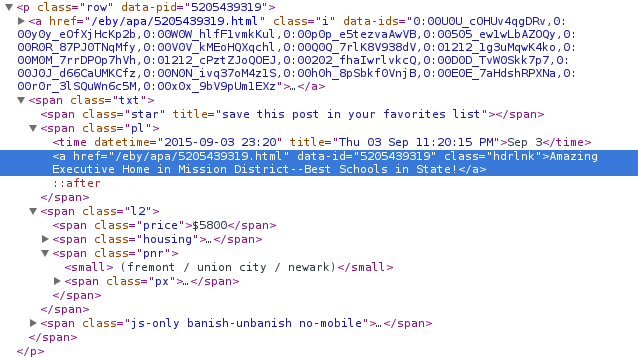
Ok... so now what? There's definitely some information we want in here, but where can we find it?
Well, here's a few things, after looking at that source:
| Information | Location |
|---|---|
| Title of posting | the text inside the highlighted <a> in the image above |
| URL of the post | the href of the highlighted <a> |
| Time it was posted | the <time> tag inside of the <span class="pl"> |
| Rent | <span class="price"> inside of the <span class="l2"> |
| Location | <span class="pnr">'s <small> tag |
Well, let's expand our example and try to get some of that pulled out! I'm going to put it into a python dict, because they're fast and are easily transferable to JSON!
source = get_craigslist_html()
rootsoup = BeautifulSoup(source)
for post in rootsoup.find_all('p', 'row'):
listing = {}
pl_container = post.find('span', 'pl')
listing['title'] = pl_container.find('a').text
listing['url'] = pl_container.find('a').get('href')
listing['time'] = pl_container.find('time').get('datetime')
if post.find('span','price') is not None:
listing['price'] = post.find('span','price').text.strip()
if post.find('span','pnr').small is not None:
loc_raw = post.find('span','pnr').small
# get rid of the surrounding () & whitespace
listing['location'] = loc_raw.text.strip()[1:-1]
How neat is that?

Great, if we have one of these dictionaries per listing we can assemble them all together and query them as a group!
def get_craigslist_index(url):
source = get_craigslist_html(url)
rootsoup = BeautifulSoup(source)
posts_from_page = []
for post in rootsoup.find_all('p','row'):
try:
listing = {}
listing['repost'] = 'data-repost-of' in post.attrs
pl_container = post.find('span', 'pl')
listing['title'] = pl_container.find('a').text
listing['url'] = pl_container.find('a').get('href')
listing['time'] = pl_container.find('time').get('datetime')
if post.find('span','price') is not None:
listing['price'] = post.find('span','price').text.strip()
if post.find('span','pnr').small is not None:
loc_raw = post.find('span','pnr')
listing['location'] = loc_raw.small.text.strip()[1:-1]
posts_from_page.append(listing)
return posts_from_page
That's the general logic of the script I wrote, which does this for multiple pages until it hits a desired amount of results.
Now that we have the right tool for this job, let's download some posts!
Running It

After running this command, all results are stored in sfbay-apa.json. We're now going to use the excellent command-line JSON processor jq to, well, process our JSON.

Let's say I'm looking for Craigslist-listed apartments in Sunnyvale (which I am). This is the filter string I put together to do that:
.[] | (.location=="sunnyvale") then .url else empty end
The part before the pipe (|) will output every element of the list at the top-level of the JSON (for those of you reading along, line 61 of cdump.py). This then pipes each of those into a conditional statement that checks if the "location" field of the dictionary matches the string "sunnyvale". If so, it'll output the "url" field, or nothing (empty) if not.
So, this ought to output a list of URLs we'd be interested in (apartments listed on Craigslist for rent in Sunnyvale).
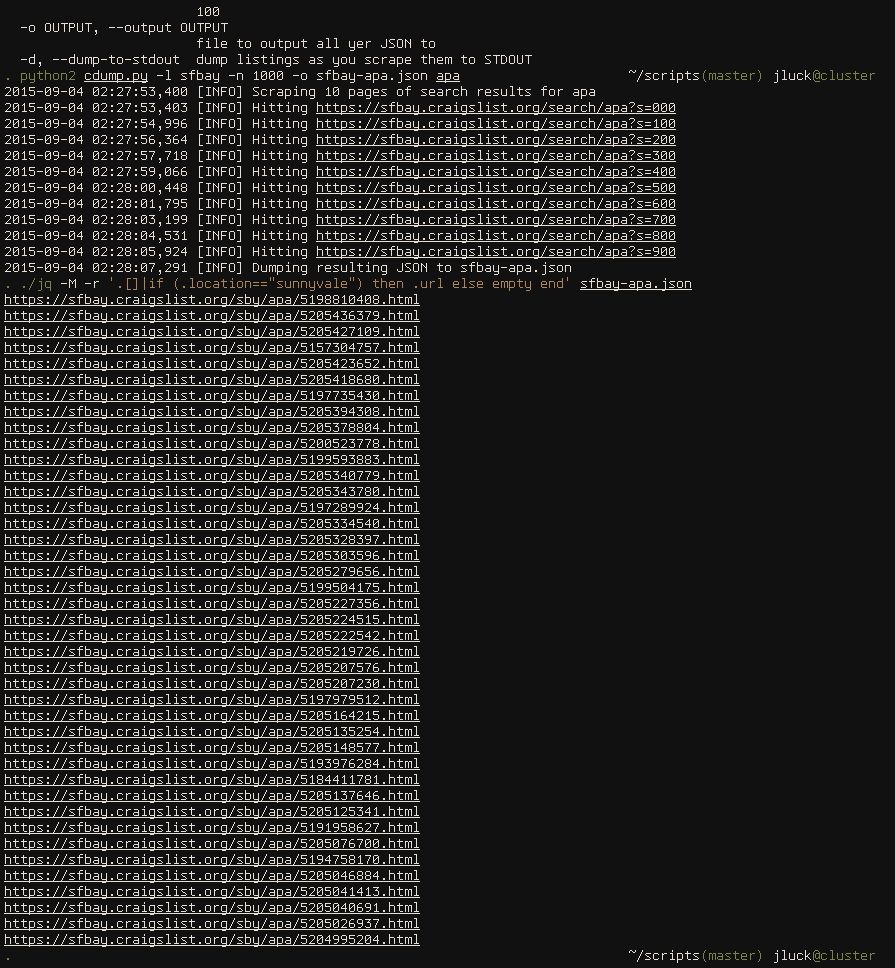
It did! Now if we set up a quick, poorly written bash loop, we can open them all at once.

And, my web browser is surprisingly not dead.

Results
I spent 2+ hours doing something I could have done in 30 minutes. I'm now wallowing in the irony.